Aurora DSQL scales to zero
The Amazon Aurora DSQL landing page leads with:
Amazon Aurora DSQL is the fastest serverless distributed SQL database for always available applications. Aurora DSQL offers the fastest multi-Region reads and writes. It makes it effortless for customers to scale to meet any workload demand with zero infrastructure management and zero downtime maintenance.
Fantastic availability is definitely one of the benefits of the DSQL architecture. If you have a single point of failure then of course you’re bound by the availability of that single thing. If it fails, or if connectivity to it fails, then you’re down. That’s why you can’t rely on a single node - it’s why you need a distributed system. Once the system is capable of running across multiple nodes, you might as well run those nodes in different Availability Zones or AWS regions.
If all of this sounds expensive, well, that’s the point of this article.
Historically speaking, you’d be right to be worried about cost. Historically speaking, improving availability has been about buying expensive hardware to improve reliability, plugging in redundant power and networking, or paying expensive licensing fees for proprietary systems.
But DSQL changes all that. There is no “cheap” version of DSQL that has poor availability, doesn’t scale, and makes you manage infrastructure. There isn’t a license fee or long-term commitment to make before you get the real deal. With DSQL, you get the same effortless scaling and operations at any scale. Even if you’re on the Free Tier.
Scaling up, scaling down
When we say scale to meet any workload demand, we don’t just mean scale up, we mean scale down too. You see, when you connect to DSQL, it looks something like this:
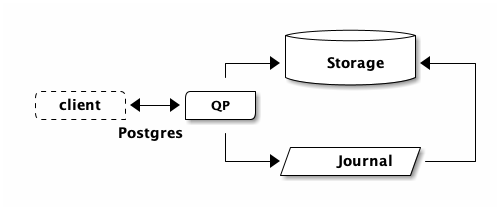
If you open another connection, now you have two clients and two query processors (QPs):
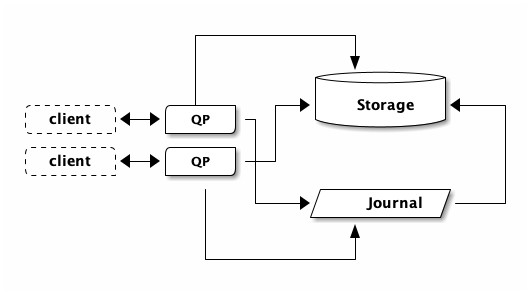
These connections can be from a single process, or from multiple processes running on different machines (such as from AWS Lambda). DSQL doesn’t care how you’re connecting. These QPs are independent resources. This is part of the secret sauce of availability. If the hardware running one of those QPs fails, then it is unlikely that the other QPs will fail at the same time in the same way.
It’s really worth pausing here. If you’re thinking “hmm, that seems expensive”, I get it. After all, historically speaking, each node is expensive. It looks like we’ve just added another node. It looks like connecting is going to be slow. It looks like I need to either provision this node somewhere, somehow, or tell DSQL up front how many QPs I need. Nope.
Where do QPs come from?
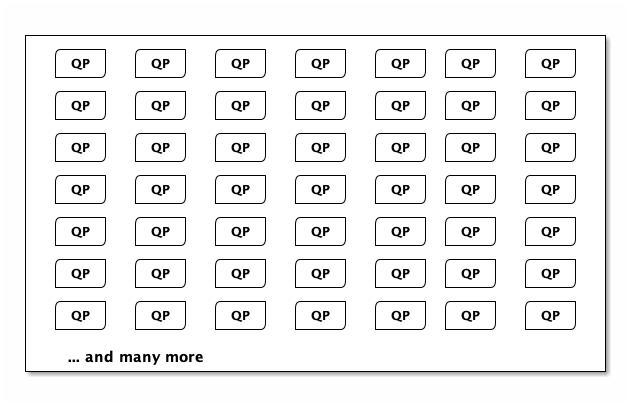
Each QP is a Postgres process running inside a Firecracker MicroVM (μVM). Firecracker is open-source technology, built by AWS, that blends the security benefits of hardware virtualization with the speed and resource efficiency of containers.
A QP is actually just a tiny slice of a machine. Here’s a machine running a bunch of QPs that are ready to go. They’re just sitting there, waiting:
When you connect to DSQL, DSQL will assign a QP to that connection. The green box shows which QP was selected:
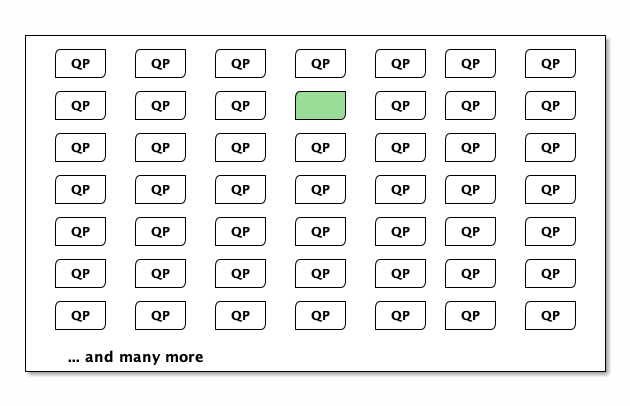
It’s important to note that this machine isn’t yours - it’s DSQL’s. You’re just borrowing some capacity on it.
Somebody else can borrow some capacity too. If another customer opens 100 connections, some of those might land up on the same machine. Here, we show in yellow that 2 QPs were chosen on the same machine:
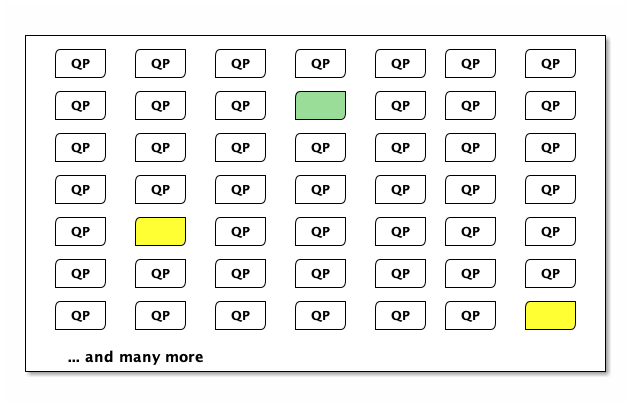
As the green customer, you won’t notice the yellow customer. You’re running in a virtual machine, and are isolated from all other customers. The same is true for the yellow customer. The yellow customer can’t even tell they have two connections on the same machine.
Disconnecting
If we disconnect, the μVM is destroyed:
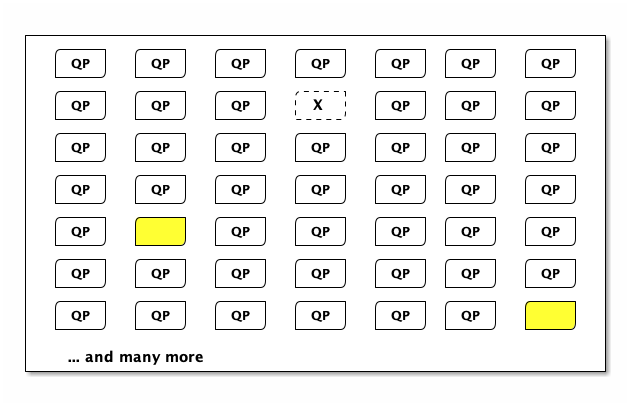
… and then the pool is refilled:
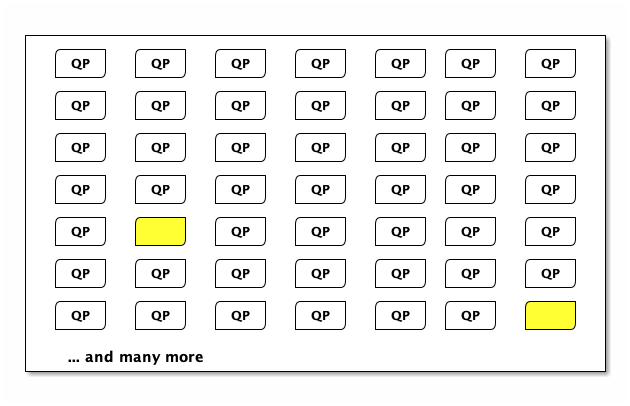
Refilling the pool is fast thanks to Firecracker - μVM launch in milliseconds.
If we’ve hung up all our connections, what does our cluster look like?
Is that what you were expecting?
DSQL was designed to “scale to zero”
While we were designing DSQL, we met frequently with customers and members of the AWS Hero community to ensure we are building the right thing. The feedback we were given time and again is: “Where is the relational version of DynamoDB?” and “Will DSQL scale to zero?”
What customers love about DynamoDB is that there is truly no underlying instance to worry about. There’s nothing to resize, nothing to patch or upgrade, and no single point of failure to worry about.
If you create a DynamoDB Table and insert some data, then you pay for the requests to insert that data. If you don’t make any more requests, then you will only pay for storage. There isn’t a need to pay an hourly instance price, because there truly isn’t an instance to pay for.
If you come back to your Table after a few days of not using it, you can immediately make read or write requests. Again, this is by design. There’s simply no need to spin up an instance to process those requests, because that’s just not how DynamoDB works.
Like DynamoDB, DSQL was designed to scale to zero. If you close all your connections, then you simply aren’t using any QP capacity. If you aren’t using any capacity, then there’s really no need to charge an hourly rate for compute. Like DynamoDB, an idle DSQL cluster only pays for storage.
In this article, I’ve only described how the QP scales both up and down. What about the other components? They have a story too. Each part of DSQL was designed to scale both up and down based on the load given to the system. The real architecture is much more complex than I’ve shown here. Maybe we’ll cover that in a future article!
Takeaways
DSQL has been designed to scale both up and down. When we talk about “scale to meet any workload”, we really mean it. We don’t just mean up, we mean down too. How far down? All the way to zero.
With DSQL, you only pay for requests and storage. If you have a cluster with $10 worth of data (about 30GB) that you make zero requests to in a month, then at the end of that month you will pay $10 for storage and $0 for requests.
Because the service has fundamentally been designed to scale horizontally in tiny increments, DSQL considers going from 0→1 connections to be really the same thing as going from 99→100 connections. In either case, you need another QP!
As a consequence of this design, DSQL is able to offer both per-request pricing with no upfront commitments as well as the ability to rapidly scale up from zero.