Aurora DSQL Best Practices: Avoid hot keys
In the Circle of Life, I describe the flow of data in Aurora DSQL. Data flows from the Query Processor (QP), through the journal, and into storage. Once in storage, it can be queried by future transactions.

There are many things to love about this design. My favorite is the elimination of eventual consistency, at any scale, even when running in multi-Region configuration. Pretty cool.
In today’s article, I want to share a pattern that doesn’t work well with this design: hot keys. What is a hot key? What are some examples of hot keys? Why don’t hot keys work well on DSQL? What should I use instead? Is this a forever limitation? All this and more… coming right up.
But first, let me tell you the good news: you don’t have to worry about scale if your application spreads writes over a well distributed range of keys. Furthermore, in DSQL you (mostly) don’t have to worry about scaling for reads (even in read-write transactions). Let’s jump in!
Updating rows in DSQL
Let’s say we have a simple blog hosted on DSQL:
create table posts ( id uuid primary key default gen_random_uuid(), title varchar, visits int ); insert into posts values ('my favorite restaurants', 0);
Every time a visitor comes along, we bump the number of visits:
update posts set visits = visits + 1 where id = ?;
What’s happening under the covers when DSQL processes this update? First, DSQL needs to read the latest row from storage:
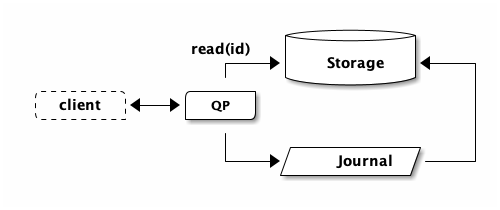
If no rows were returned, we’re done. The query would return a row count of 0:
=> update posts set visits = visits + 1 where id = ?; UPDATE 0
However, in our case we’ve picked blog post that does exist. The QP now has the latest data in memory, and it updates the row. I’m going to use JSON to illustrate, because most of you don’t speak Postgres’s binary format:
{
"id": "edd54beb-3a86-4849-ab29-051ccba004c1",
"title": "my favorite restaurants",
"visits": 0
}
Next, the QP is going to update the row to the new value:
{
"id": "edd54beb-3a86-4849-ab29-051ccba004c1",
"title": "my favorite restaurants",
"visits": 1
}
And finally, we’re going to commit:
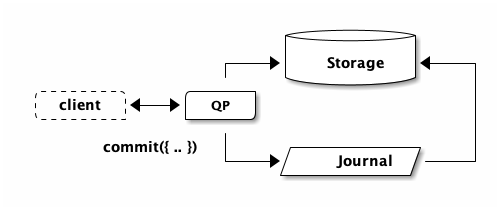
That’s it! Transaction complete. Later, storage is going to read from the journal and apply the update:
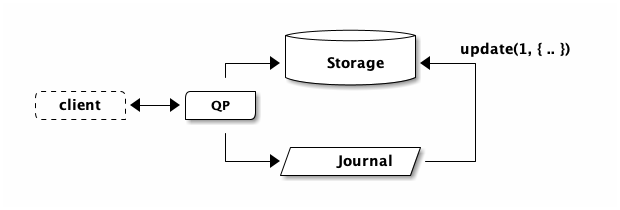
While we were doing that, we had another visitor. I have great taste, and so everybody wants to know what restaurants I like..
update posts set visits = visits + 1 where id = ?;
What now? Well, same deal. Except we need to ensure the row that the QP fetches
has the updated visits, so that when it does visits = visits + 1 we get the
right answer. As I discussed in the Circle of Life, we use time to ensure that
storage has seen all the updates. We’ve put a lot of engineering effort into
making sure that storage already has the data by the time the next query comes
around, so that there is no need to wait.
Throughput and latency
Let’s pretend that the latency between the QP calling commit and storage receiving the update is hypothetically 1 second (this number has been chosen for easy math). How many times can I update this counter per second? Little’s Law!
So, if the QP→journal→storage path takes 1 second, then we can only bump the visit counter once every second:
\begin{equation} Throughput = \dfrac{1}{1s} = 1 \end{equation}Let’s put that into practice. I setup a test workload that ran exactly this workload from an EC2 instance in the same region as my cluster:
- Commit latency (p50)
- ~7ms
- Transactions per second
- ~140
Does Little agree?
\begin{equation} Throughput = \dfrac{1}{Latency} = \dfrac{1000}{7} = 142 \end{equation}This is absolutely not the best use of DSQL. We’re getting 1.5KiB/sec of total throughput. Sad trombone.
Of course, in this hypothetical system, the overall system (blog) isn’t limited to 140 visitors per second. It’s any single page that’s limited. The problem is with the hot key (the counter), not the table, and not the cluster. For example, if we add another post:
insert into posts values ('why peaches are the best fruit', 0);
That post can also count views at ~140tps. Which means our hypothetical blog can sustain up to 280 visitors per second if our visitors spread their interest over both posts.
What exactly is a hot key? A hot key (or row) is a row that is experiencing a high volume of read or write requests. Rows can be “hot for read” or “hot for write”. In our example, we’d say the key is hot for write, because it has approached the speed limit of how frequently any single row can be updated.
Hot for read
Let’s pretend we eliminated our visit counter. What happens if our restaurant article starts to get popular? Each visitor needs to read the post row. At this point, the post will experience more read heat. There are more and more QPs hammering on the same row. As discussed in the Circle of Life, DSQL will detect this read heat and add more storage replicas:
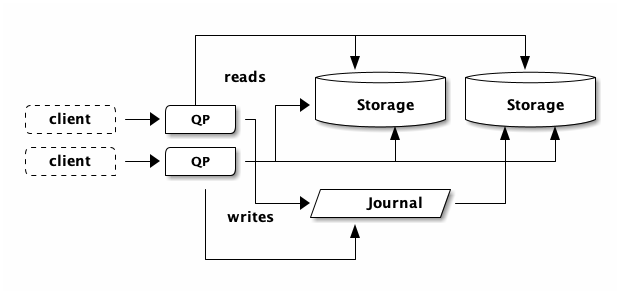
In DSQL, it’s usually not a problem to have hot for read keys. As read heat increases, DSQL will automatically scale out. Sudden large spikes will result in increased latency while DSQL works to bring new capacity online. In a future article, I’ll dig into how DSQL scales in more detail.
Conflicts
As it turns out, our example blog is hosted on Lambda. DSQL works really well with Lambda, because connections to DSQL are fast and cheap. But that’s a story for another day.
The question for today is: what happens when two people try and visit the same post at the same time? Susan and Bobby both independently click the link. Lambda is going to process their requests concurrently, over separate connections, which means DSQL is going to see two page visits concurrently.
First, both Susan and Bobby read the current visit counter. Remember, the QP needs to read the current row to know what the new counter should be:
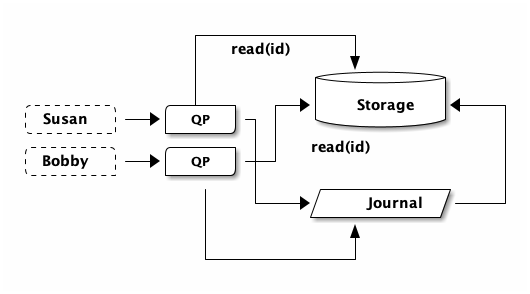
Both Susan and Bobby’s QPs are going to see the same number of visits. These QPs don’t know about each other. They’re separate processes, likely on different physical machines. They both go to storage. They both see the same latest number of visits. Both QPs are going to produce the same updated row.
Which means only one of these transactions can commit. The other is going to get rejected due to a write-write conflict. In this case, Susan wins the race and commits, while Bobby’s transaction needs to retry.
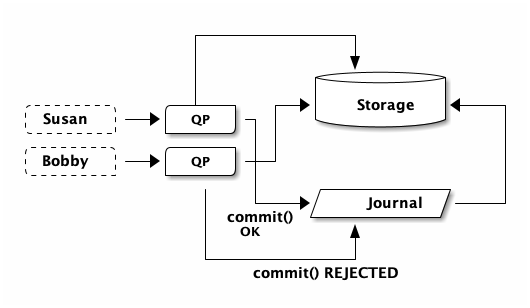
Bobby doesn’t actually know about the failure to bump the page visit counter. Bobby’s QP returns an Optimistic Concurrency Control (OCC) error to Bobby’s Lambda function, and the function tries again. Bobby may experience slightly elevated page load latency, but most humans aren’t going to notice 7ms.
Hot keys are anti-scale. It doesn’t matter if you have 1 client running a read-modify-write loop as fast as it can, or if you have 100 clients running a read-modify-write loop as fast as they can. You’re not going to get more modifications per second than Little’s Law allows.
Hot keys in the wild
TPC Benchmark C is an on-line transaction processing (OLTP) benchmark.
TPC-C looks like an eCommerce system. TPC-C scales quite nicely on DSQL, but the schema has some hot spots in it. Let’s take a look at two.
The “new order” transaction models purchasing an item in the system. Orders are placed in “districts”. From the description:
In the TPC-C business model, a wholesale parts supplier (called the Company below) operates out of a number of warehouses and their associated sales districts. The TPC benchmark is designed to scale just as the Company expands and new warehouses are created. However, certain consistent requirements must be maintained as the benchmark is scaled. Each warehouse in the TPC- C model must supply ten sales districts, and each district serves three thousand customers.
As part of processing an order, NewOrder.updateDistrict sets the next “order
ID”:
UPDATE district SET D_NEXT_O_ID = D_NEXT_O_ID + 1 -- update the next order id WHERE D_W_ID = ? -- for this warehouse AND D_ID = ? -- & this district
This limits the total number of orders per “district” per second. So, if somebody in your district buys a teddy bear, you need to wait for their order to complete before you can get yours in. That’s silly. All you want is that teddy bear, you don’t care about the order number! In a real application, you would probably want to avoid giving out business information too.
This is an example of a sequence. You can build a sequence yourself like TPC-C
does, or try use Postgres’ CREATE SEQUENCE or BIGSERIAL type (both are
currently disabled in DSQL). Sequences are inherently anti-scale. They can
create contention on read-modify-write loops, they can create conflicts, and
they create hot partitions within the system. Avoid sequences! For this example,
I think most people would look to something like a UUID or other random-number
technique for generating order ids.
Let’s look at another example from TPC-C. As part of processing an order,
Payment.updateWarehouse rolls up payment information at the “warehouse” level:
UPDATE warehouse SET W_YTD = W_YTD + ? -- sum the year-to-date dollars WHERE W_ID = ? -- for this warehouse
This limits the total number of payments per warehouse per second, as each payment needs to read the current YTD amount of sales made from this warehouse, add the amount made by the current order, then produce a new row. This means that even though “Each warehouse [..] supply ten sales districts”, only one of those districts can process an order at the same time.
If you run into a pattern like this, ask yourself what you’re really trying to
do. Does it matter that you have a strongly consistent sum of sales for the
current year per warehouse? Or, are you ok with some other reporting mechanism?
In TPC-C, there is a payment history table and you can run sum() queries over
that table to compute whatever you want. Current day, current month, just one
customer - whatever you want.
The payment history table is also the solution to our visitors problem. If we created an access log like this:
insert into visits (post_id, visited_at, referral_url, user_agent, -- etc. values ( -- etc.
Then we can use SQL to analyze visits in whatever way we want. You can compute total visits by post, or trending pages this month, or top referrers, or… Way more flexible, and no hot key!
Now, let’s look at a counter-example. What about the “update stock” query, that runs as part of the new order transaction?
UPDATE stock SET S_QUANTITY = ? , -- lower the quantity of stock S_YTD = S_YTD + ?, S_ORDER_CNT = S_ORDER_CNT + 1, S_REMOTE_CNT = S_REMOTE_CNT + ? WHERE S_I_ID = ? -- for this item AND S_W_ID = ? -- in this warehouse
This is a good example of what to do on DSQL. There are only so many teddy bears in stock. You need to check if there is stock before selling one, and you need to update stock after a sale. This example is going to scale well on DSQL: presumably there are many different products being sold concurrently, and so each item can be sold and accounted for separately.
What about other databases?
Hot keys are a problem on every database, not just DSQL. However, each database has its own strengths and weaknesses, and so the story plays out differently.
On instance-based Postgres, such as RDS, the read-modify-write loop is way
faster because the latest row value is usually available in memory. Commits may
also be quicker, depending on the durability model (“can I lose data?”) of the
service you’re using. If you’re running Postgres yourself, a commit may be as
simple as a fsync() to ensure the Write Ahead Log is made durable to local
storage. But, if that storage device fails, you’ve lost data. On Aurora
Postgres, commits are only acknowledged after being replicated to multiple
availability zones… which takes time. This improves durability, adds commit
latency, and therefore limits TPS for hot keys.
There are many ways to Implement resource counters with Amazon DynamoDB. Hot keys have a maximum update rate of 1000/second, which you can achieve by using update expressions to explicitly instruct the underlying partitions to increment a counter:
$ aws dynamodb update-item \ --table-name counter \ --key '{"pk":{"S":"abc123"}}' \ --update-expression "ADD quantity :change" \ --expression-attribute-values file://values.json $ cat values.json { ":change" : { "N" : "-5" } }
In the fullness of time, we expect to be able to teach DSQL some of these optimized access patterns, which will increase the throughput on a single key. But never to infinity.
No matter the database you choose, you’re going to find a limit to the throughput you can get on a single key. For this reason, many applications find themselves having to rethink their schema as they scale.
Summary
In this article we’ve taken a deep dive into why hot for write keys can prevent your application scaling on DSQL. When designing your schema, keep an eye out for sequences and statistics, such as counters or sums.
DSQL has been designed to scale horizontally, so take advantage of that as you design your schema.