Aurora DSQL: The Adjudicator
This article is about an internal component of the Aurora DSQL architecture that we call the Adjudicator. I’d recommend reading at least my article on the Circle of Life or Marc Brooker’s blog on Transactions and Durability before continuing with this one.
Unlike other distributed databases, DSQL fully decouples reads and writes. In order to commit a transaction, we just need to durably record it in the journal. If only it were so simple. The Adjudicator’s job is to abstract over the many (many) challenges in getting this right.
Conflicts
The first design challenge is: am I even allowed to commit? Consider a transaction to pay a debt:
SELECT balance FROM accounts WHERE id = 1; -- returns 100 -- application checks: are there sufficient funds? -- -> yes UPDATE accounts SET balance = balance - 100 WHERE id = 1; -- now the credit UPDATE accounts SET balance = balance + 100 WHERE id = 2;
This transaction should commit on its own, but if another transaction
concurrently tried to deduct funds from the same account (id 1), then only one
should be allowed to commit.
DSQL does these checks optimistically at commit time. In a pessimistic system,
the first transaction to UPDATE id 1 would hold a lock until commit time, and
the second transaction would wait on that lock.
The Query Processor (QP) and Adjudicator work together to implement this. The QP assembles a transaction that looks (conceptually) like this:
transaction: start_time: xxx writes: accounts: 1: { balance: 0 } 2: { balance: 200 }
You’ll be pleased to know we do not, in fact, use YAML in DSQL.
The Adjudicator will check if any of proposed changes conflict with any other recently written keys, based on the transaction’s start time. Because DSQL is using accurate clocks and never serves stale reads, any transaction that started after a key was last written is therefore guaranteed to have seen the latest data.
If all checks pass, the Adjudicator picks a commit time, then atomically commits the transaction to the journal (more on this later).
Pipelining
The journal’s API supports pipelining, which is to say that the Adjudicator doesn’t need to wait for an acknowledgment before committing the new transaction. This is important because replication across Availability Zones (or AWS Regions) takes time, and we don’t want to be waiting.
In order to support this, writes are pre-conditioned in some way. The journal has several features to support this. The simplest one to explain is “expected sequence number”. This allows the Adjudicator to blast writes at the journal:
- sequence=1, expected=0: [record some data]
- sequence=2, expected=1: [record some data]
- sequence=3, expected=2: [record some data]
Without pipelining, every one of these 3 writes would need to wait on replication. For example, if replication took 3ms, then we’d be looking at 9ms in total. With pipelining, the total time is reduced to ~3ms.
This is safe because failure cascades. If the write at sequence=2 is
rejected, then the write at sequence=3 is also rejected, because the journal
never reached sequence=2 to satisfy its expectation. The Adjudicator can’t
end up with partial or out-of-order commits.
Expected sequence numbers are one of the first such features the journal added, but they’ve since added concepts such as “generations” that we make heavy use of. So, why would your expectations not match reality? Let’s talk about failure.
Side note: both the Adjudicator and journal are written in Rust, and are based
around async concepts.
Availability
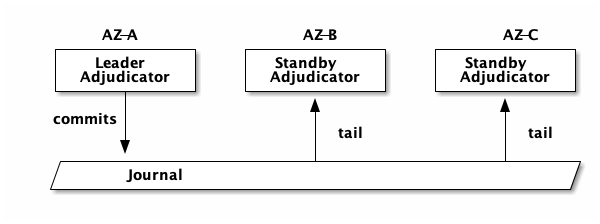
If an Adjudicator explodes immediately after committing the transaction, the transaction is still durable. Standby Adjudicators (in other Availability Zones) are tailing the journal and learning about all the committed transactions. In addition to committing transactions, the leader also writes heartbeats into the journal. These heartbeats serve multiple purposes (see The flow of time in the Circle of Life), including failure detection of the leader.
If a standby detects the leader has become unavailable, it will try and become the leader. As previously mentioned the journal’s API provides us tools to not only elect a new leader, but to also fence off the old leader. Consider:
- Adjudicator A is the leader, and temporarily loses network connectivity
- B becomes the leader
- A regains connectivity, attempts to record a transaction
The journal guarantees that A’s attempt to commit will be rejected.
Together, these properties mean that DSQL can recover from failure extremely quickly (hundreds of milliseconds). Obviously, the Adjudicator itself is rock solid and doesn’t crash, but infrastructure failures do happen from time to time.
We’ve also optimized for graceful handover, so that we can deploy with even less impact. This is really important to us, because it allows us to deliver features and performance updates to customers without the need for maintenance windows.
Journals
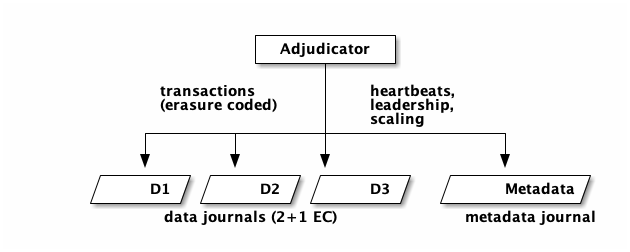
The Adjudicator writes transactions to multiple data journals, using erasure encoding. We do this to lower tail latency. The journal is an unbelievably awesome piece of software, with near perfect latency at every percentile. But tail latency is still a thing, and picking multiple independent paths is a great way to deal with outliers.
Adjudicators also have metadata journal that they use to record heartbeats, coordinate leadership changes, and orchestrate scaling. Because there are multiple journals, actually enacting a leadership change is somewhat involved, and I won’t go into it here.
Scaling
The Adjudicator needs to scale when it runs out of CPU doing actual adjudication, or when the journals run out of bandwidth. In order to scale, the Adjudicator needs to hand over part of the “keyspace” to another Adjudicator.
If a cluster is operating at really low scale (remember: DSQL scales reads and
writes independently; I’m only referring to write scale here), then we only
need a single range. Back to our original example: we submitted a transaction
that updated accounts id 1 or id 2 (in a Postgres schema). This is mapped
into a single adjudication range.
As we add, remove, and updated rows more and more frequently, the Adjudicator
will report write heat. More specifically, it will track where the write
heat is. Is it uniform, Zipfian, or something else? This information will be
used to generate split points. Effectively, the Adjudicator might decide that
it should only handle accounts 1 to 1000 while some other Adjudicator should
handle all other accounts. Similarly, we might merge ranges back in. If you do
a large data load (lots of writes), and then only read the data, there is no
need to keep so much infrastructure lying around idle. This is all entirely
dynamic, based on actual demand.
2PC
If a split caused id 1 and id 2 to be owned by different Adjudicators, DSQL
still needs to ensure atomicity. With traditional two-phased commit, the happy
path looks like:
- QP -> Adj[1]: Check and Lock id=1
- QP -> Adj[2]: Check and Lock id=2
- QP -> Adj[1]: Commit
- QP -> Adj[2]: Commit
There are many unhappy paths. If the Adjudicator for id 2 fails, then id 1
becomes locked. Or the QP could fail. 2PC is fairly well understood, but even a
correct implementation can be operationally unpleasant.
Instead, DSQL picks one of the Adjudicators to be the committer. Let’s say we
pick the second Adjudicator. The QP will send the entire transaction to the
first Adjudicator which will do concurrency control on id 1, then forward
the transaction to the second Adjudicator which will do concurrency control on
id 2, then atomically commit the entire transaction.
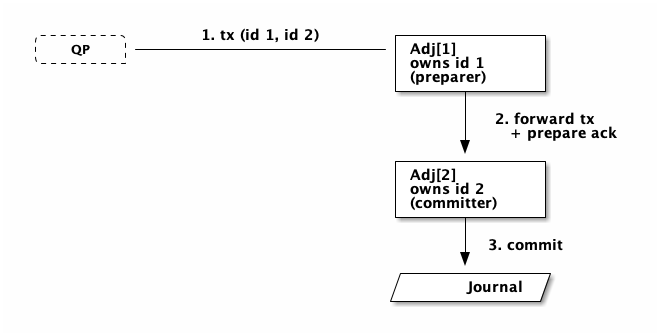
The forwarded commit has a timeout on it, which is bound by the (tiny) lease duration that we already use for leadership. This design means there is no need to do any cleanup if anything fails.
This design is also optimized for network round-trips, and we’ve taken the time to implement parallelism where possible so that transactions that touch many Adjudicators don’t take proportionally longer.
There are many things to like about this design. In addition to what I’ve already explained, there is never a need to reshard to rebalance load across the commit protocol itself - the daisy chain works across any partition layout, so the only resharding we do is the kind described in the Scaling section, which is about adding or removing capacity. One downside of this design is that for any key, it may be updated anywhere. This makes consuming the journal more challenging than in a traditional design. As it turns out, consuming an infinitely scalable journal is just hard no matter what you do, and I’ll explain how we solved in that in a future article.
Multi-Region
In a multi-Region deployment, each DSQL cluster has its own Adjudicators with active redundancy in three Availability Zones. Their journals are synchronized through the multi-Region Journal system, which I won’t explain here. The important thing to understand is that all the journals are magically kept in sync. Practically, this means that there is still only a single leader for a keyrange.
Adjudicators encapsulate this problem for the QP, which simply commits to its local region. If the leader is in another AWS Region, the Adjudicator will proxy the request over the WAN. The commit will then be replicated back. It doesn’t really matter where the leader is, since in either case DSQL must ensure the other Region has acknowledged the commit for it to be considered durable.
Future stamping
The commit timestamp is picked by the (committer) Adjudicator. This value is picked to be a time “in the future”. We use a combination of the TimeSync service and ClockBound library to pick a starting value, then additionally pad that time out to account for replication delay (which the Adjudicator monitors closely). Consider this timeline, with fictitious numbers:
- A transaction starts at
T=1 - It attempts to commit
T=5 - The Adjudicator knows the current time is ~=T=5=, but clocks are unreliable
- It knows for sure the time is in the range
(4,6) - It selects the more conservative value
T=6 - Replication delay is known to be another 1 (unit of made up time)
- It pads the commit time to
T=7 - It commits (actual time is still
T=5) - The ack is held until
T=7 - The commit is ack’d
What’s useful about this is that writers pay for replication delay, not
readers. DSQL never serves stale reads. After the commit completes, a reader
will pick a start time T>=7 and not have to wait to see the latest data.
This is a wild trick. Imagine AWS launched a Region on the moon, and you had a multi-Region setup between US, EU and moon. In this design, DSQL would offer single-digit second commit latencies, while all other reads and writes would continue to be local, fast, and strongly consistent.
Other SQL features
The Adjudicator is not constrained to only offering write-write conflict
detection. Let’s talk about two features that DSQL doesn’t currently offer:
foreign keys and SERIALIZABLE. Every now and then a customer will ask us if
our architecture makes this kind of feature hard or even impossible. Nope! It’s
really quite simple, and by far the least difficult part of this system.
Let’s extend our banking example. We might want to maintain an audit table of all debit-credits:
-- as before: do the payment INSERT INTO audit (payer_id, payee_id, amount) VALUES (1, 2, 100);
If you wanted to ensure referential integrity then you’d want DSQL to reject a subsequent transaction that tried to delete one of the accounts:
DELETE FROM accounts WHERE id = 1;
NOTE: If this delete was run concurrently with the payment DSQL would reject
one the transactions because of a write-write conflict on id 1.
With no concurrency, doing this is simple. The QP will look at the schema and
note the foreign key. Then, it will query the audit table for any payer_id
or payee_id with the value of 1. If there are any, the transaction must be
rejected.
But of course, there’s a race condition here - what if we concurrently added a
row that depends on id 1 while simultaneously deleting it?
In order to implement this, DSQL needs to inform the Adjudicator about a write-exists conflict. So the transaction might look like:
transaction: start_time: xxx writes: accounts: 1: DELETE
Meanwhile, other transactions that are trying to refer to id 1 are asking
the Adjudicator to ensure the row still exists:
transaction: start_time: xxx writes: audit: $uuid: { payer_id: 1, payee_id: 2, ... } exists: accounts: [1, 2]
Compared to write-write conflicts, which you express by either writing a row or
using SELECT .. FOR UPDATE, existence checking doesn’t conflict with other
existence checks, nor does it conflict with writes that change (vs. delete) the
row. The actual Adjudicator language is, of course, a bit more involved than
what I’m illustrating here.
The SERIALIZABLE isolation level can also be expressed naturally in this way.
The QP simply needs to track what was read, and ask the Adjudicator to ensure
that nothing it read was changed since it started its transaction.
Summary
The Adjudicator is a critical part of the DSQL architecture, responsible for concurrency control, atomicity, durability across Availability Zones or Regions, and automatically scales to handle write throughput.
The design leverages active redundancy via the replicated state machine pattern, making heavy use of the battle hardened journal service.
We’ve spent significant time in this component. I haven’t covered everything in this article. It’s written in Rust, which gives us great performance and reliability. We’ve used formal methods to ensure our protocols are correct, have build-time tests to ensure our implementation matches the specifications, and do Game Days either by ourselves or in conjunction with the journal team.
We’ve optimized for network round-trips, and ensured our cross-shard commit protocol has the lowest possible latency, and recovers automatically and immediately when things fail.
The Adjudicator is a key part of the magical experience of running an application on DSQL. Our investments in near-zero downtime recovery from failure or changes in topology mean that we can scale clusters quickly in response to surges in demand. As a DSQL customer, you don’t need to provision capacity, or pick shard keys. You don’t need to do anything for High Availability - that comes out of the box. These properties aren’t an accident, they’re precisely what we designed for, and why we put so much time into building and testing the Adjudicator!